Network Nodes Meeting, 4th October 2024
What happens if you ask representatives from 11 different research performing and supporting institutions to think about how reproducibility ready their own institution is?
On 4th October, the contact persons of our node members met in Utrecht to learn from each other and to get to know each other during NLRN’s first network meeting.
We used the framework of the Knowledge Exchange (KE) report on reproducibility at research performing organizations to systematically think through enablers and hindrances of reproducible research.
In small groups, we first categorized our own institutions into how reproducibility ready they are. The KE report suggests three levels of readiness; 1) there are some pockets of excellence; 2) efforts are partially coordinated and 3) there is organizational level commitment with coordinated processes. We concluded that those levels would depend on which disciplines, departments and research methodologies you are considering. We often encountered that there are differences between management levels and researchers: it can be that the university-wide management sets policies to foster reproducible research, but this might not trickle down to an individual researchers’ work. This might even lead to window dressing or “open washing” where institutions present themselves as committed to open research practices but the culture within the institution didn’t change.
The second discussion exercise was about enablers of reproducible working such as training, mentorship or recognition. In small groups, we tried to identify which enablers are already in place and on which level, and if they indeed function as enablers. The KE report comes with an assessment worksheet for institutions that some of the participants tested.
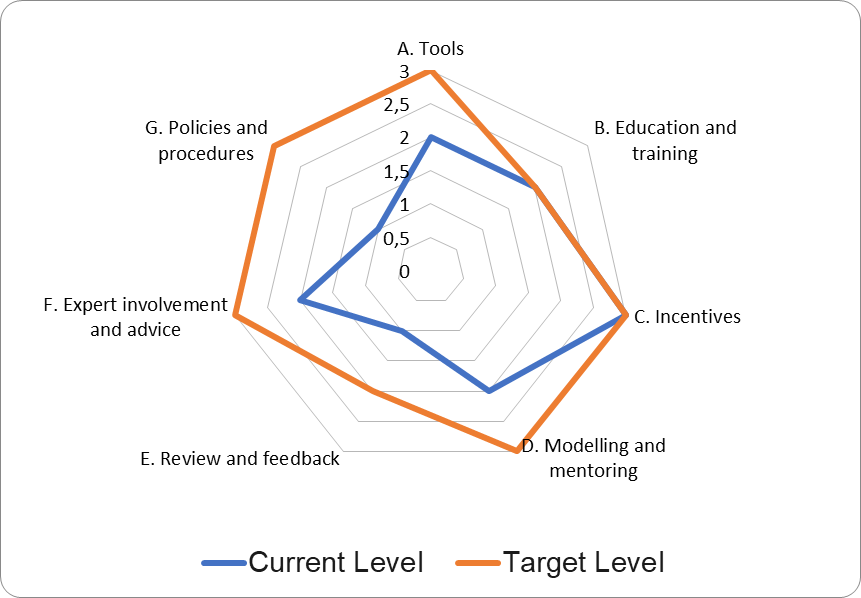
During the final discussion, we tried to figure out how the tools of the report can be used to further reproducibility in the node institutions.
The general consensus was that the tools as presented wouldn’t work as a general tool for all areas of scholarship and research. They would work largely for quantitative methodologies and would need tweaking for interpretative, qualitative, art and action based research methodologies.
The idea was raised to find an institution that would use the framework to assess their current state and work towards becoming more reproducibility ready. This process could be followed and presented as a concrete example on how the framework works.
We didn’t have enough time to talk in detail about each of the enablers. One question that was raised was if there is a hierarchy of enablers and if an institution should aim for the highest score on all of those or just some of them.
We spent a lot of time discussing training for researchers as an enabler. There were ideas of introducing reproducibility related courses to the mandatory courses at graduate schools. Others remarked that there are already a lot of training modules offered but they don’t seem to reach everyone.
The budget cuts for higher education were also discussed during this meeting with the conclusion that we need to work even more collaboratively and coordinated to make the most of the means that are already available. NLRN could play an important role in this.
In conclusion, the network event was a great opportunity to get to know each other with a lot of engagement from all participants in the discussions on the current state and future directions to increase reproducible working. In our next meeting, we will focus on concrete steps towards that future.